
[留出法 (Hold-out)] 是一種評估機器學習模型的常見方法。它將數據集隨機分為兩組:訓練集和測試集。訓練集用於訓練模型,而測試集用於評估模型的泛化誤差。
訓練/測試集劃分原則:
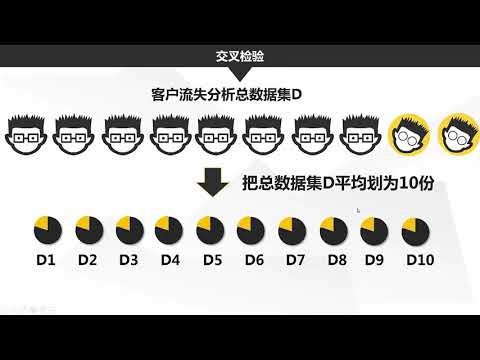

- 數據分佈一致性: 確保訓練集和測試集的數據分佈相近。
- 重複實驗: 多次隨機劃分進行實驗,取平均值作為評估結果。
- 適當的樣本比例: 通常訓練集包含 2/3 ~ 4/5 的樣本,測試集包含 1/3 ~ 1/5 的樣本。
- 測試集容量: 測試集應至少包含 30 個樣例。
實例:
包含 1000 個樣本的數據集,將其劃分為:訓練集(70%)和測試集(30%)。

變種方法:
K-折交叉驗證:
將訓練集進一步劃分成 k 個子集。每次使用 k – 1 個子集訓練,一個作為驗證集。進行 k 次訓練/驗證,根據結果進行模型選擇並調整超參數。
驗證集:
在訓練過程中使用一個單獨的驗證集進行模型選擇和超參數調整。這樣有助於避免過擬合,因為測試集不被用於參數調整。
| 方法 | 數據集劃分 | 用途 |
|---|---|---|
| 留出法 | 訓練集和測試集 | 評估泛化誤差 |
| K-折交叉驗證 | 訓練集、驗證集和測試集 | 模型選擇和超參數調整 評估泛化誤差 |
| 驗證集 | 訓練集和驗證集 | 模型選擇和超參數調整 |
關鍵概念:
- 訓練集: 用於訓練模型的數據集。
- 測試集: 用於評估模型性能的數據集。
- 驗證集: 用於模型選擇和超參數調整的數據集。
- 泛化誤差: 模型在 unseen 數據上的預期誤差。
- 過擬合: 模型在訓練集上表現過好但在新數據上表現不佳。
留出法:一種分類與概括策略
留出法是一種廣泛用於研究與評量中的分類與概括策略,它涉及識別範疇並將資料組織到這些範疇中。留出法有助於系統化複雜資料並做出意義解釋。
留出法的類型
留出法有多種類型,各有不同的目標和應用:
| 留出法類型 | 目標 | 應用 |
|---|---|---|
| 開放式留出 | 主要範疇由研究者或評量者定義 | 資格訪談、定性研究分析 |
| 深度結構留出 | 找出隱藏的結構或模式 | 質性資料分析、羣體訪談 |
| 樹狀圖留出 | 從資料中建立階層式分類 | 決策樹、聊天機器學習 |
| 聚類分析留出 | 根據相似度將資料分組 | 客户羣體分析、市場研究 |
| 軸向編碼留出 | 沿著多個維度組織資料 | 接地理論研究、民族誌研究 |
留出法步驟
留出法通常涉及以下步驟:
- 資料蒐集:準備要分類和概括的資料,例如訪談、觀察或文本。
- 開放式編碼:仔細閲讀資料並標記出關鍵概念、主題和模式。
- 軸向編碼:將開放式代碼組織到較大的範疇或維度中,這些範疇或維度可以捕捉資料中的重要關係和主題。
- 選擇性編碼:從軸向代碼中選擇最相關和有意義的範疇,這些範疇將用於最終的分類或概括。
- 組織資料:將資料組織到所選範疇中,形成一個系統化且有意義的框架。
留出法的好處
留出法提供多項好處,包括:
- 資料系統化:通過將資料分類到範疇中,留出法有助於組織複雜且無結構的資料。
- 模式識別:留出法可以識別資料中的模式和趨勢,這有助於做出合理的結論。
- 知識產生:通過組織和概括資料,留出法促進知識的產生並支持深入理解。
- 提升客觀性:留出法提供了一個系統的框架來分類資料,從而提升分類的客觀性和一致性。
- 簡化溝通:使用範疇來組織資料可以簡化與其他研究者、評量者或利害關係人的溝通。
留出法的限制
儘管有許多好處,留出法也有一些限制: